Speed vs Rigor
Startups move fast and break things. Big companies build slowly with more rigor. This is an accepted truism in our industry.
But why is this the case? Is one culture strictly better than the other? Is either speed or rigor an ideal we should always strive for?
The tradeoff
Speed and rigor exist along a spectrum. You have to trade off one for the other.

Moving fast will break things. It’s easy to build a cool prototype with Claude Code at a hackathon. It’s way, way harder to build a service with millions of users and 99.99% uptime, with or without AI tools.
The reason is simple: it’s more work to build for performance, reliability, and scale. Entropy, not order, is the natural state of the universe. It’s more work to design clean architecture and abstractions, to achieve good testing and observability coverage, to ensure accessibility and compliance, to establish effective operating processes. Rigor doesn’t come for free. It comes at the cost of engineering resources, whether human hours or AI tokens, and the opportunity cost of whatever else they could have been applied to.
Finding the sweet spot
Because of this tradeoff, on every team at every company, we have to continuously adjust where we want to be on the speed-rigor spectrum, given our current resources and business goals.
The best way to think about it is through the lens of diminishing returns. For a given set of goals (scale, performance, reliability, etc.), there’s going to be a sweet spot in terms of speed vs rigor.
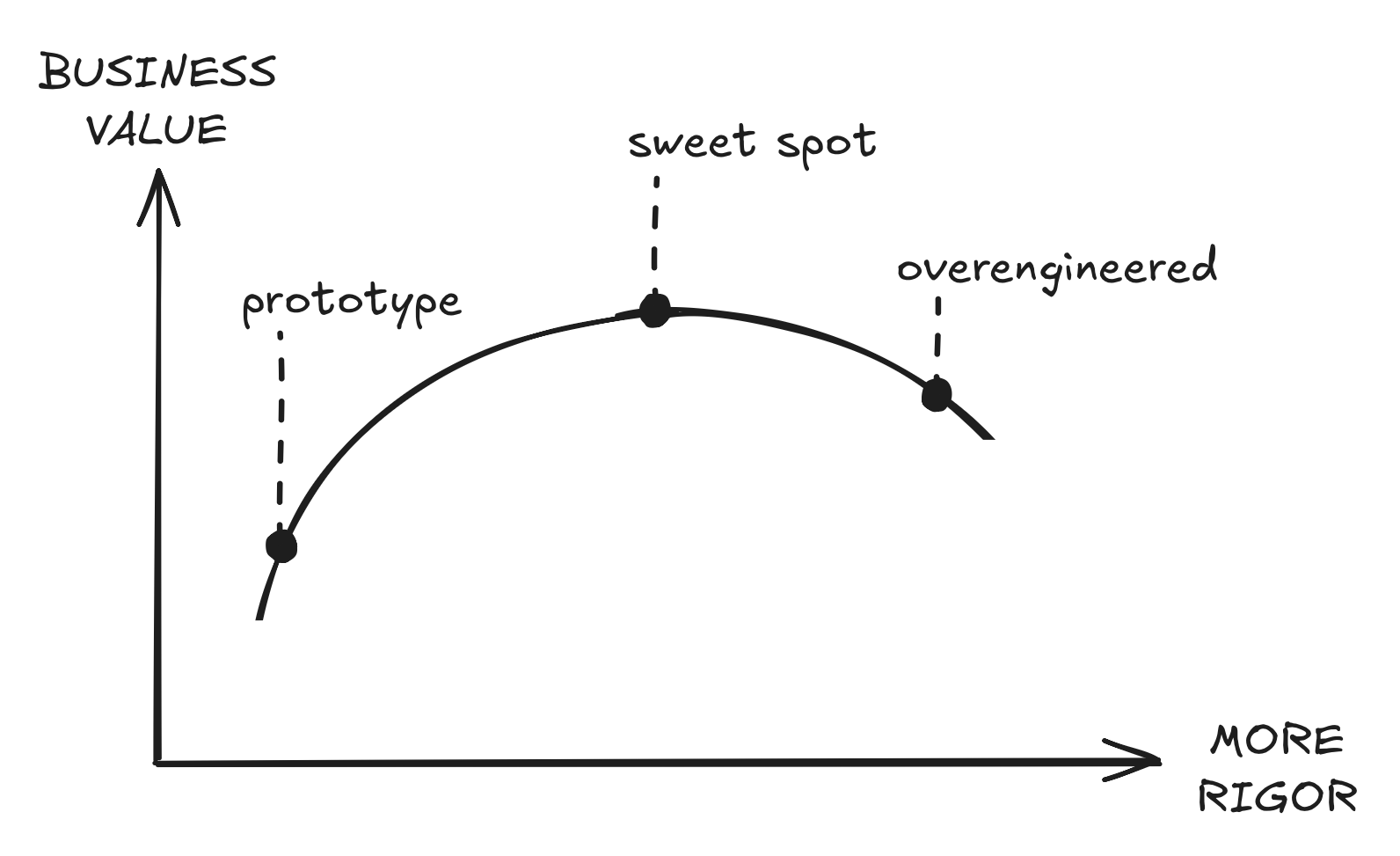
Starting at the left-hand side, we’re in the prototype stage of things. The system mostly works, but might have poor code quality, no tests, logging or monitoring, poor performance and reliability, doesn’t scale past a few users, has major bugs and security vulnerabilities, and no internal tooling.
As we continue to invest time and tokens, we move to the right and things improve drastically. Major bugs and performance bottlenecks get ironed out. Clean abstractions and good tests are introduced. The infrastructure scales to 10K, then 100K, then 1M users. It’s obvious that improvements are worth the investment. They’re allowing us to bring in more users, making users happier, and converting more of them to paid customers.
But as we continue to invest, it becomes harder and harder to make further improvements. We’ve already picked all the low hanging fruit. Maybe we've already optimized the original Python backend as far as we could, and getting to the next level of scale now requires rewriting the whole thing in Rust. Maybe we have to rework the entire data layer in order to support sharding, a write-through caching layer, multi-cell and EKM. More and more, projects go from taking an engineer days or weeks to now taking entire teams months.
At some point, we’ll find the incremental business value from further investments to not be worth the cost. Designing for 2x capacity headroom makes sense. 20x feels excessive; 200x is almost certainly pointless. As it gets more and more expensive to get to the next level of rigor, the opportunity cost also grows: new features, bug fixes, and anything else we could be doing instead. Unless we believe the business is actually likely to need 20x or 200x scale in the next 1-2 years, those engineering resources could probably yield more value if applied elsewhere.
Scaling up
Over time, as the business grows and our goals evolve along with it, the curve shifts up and to the right. With increasing scale, performance and reliability needs, the sweet spot moves towards requiring more and more rigor at the cost of speed.
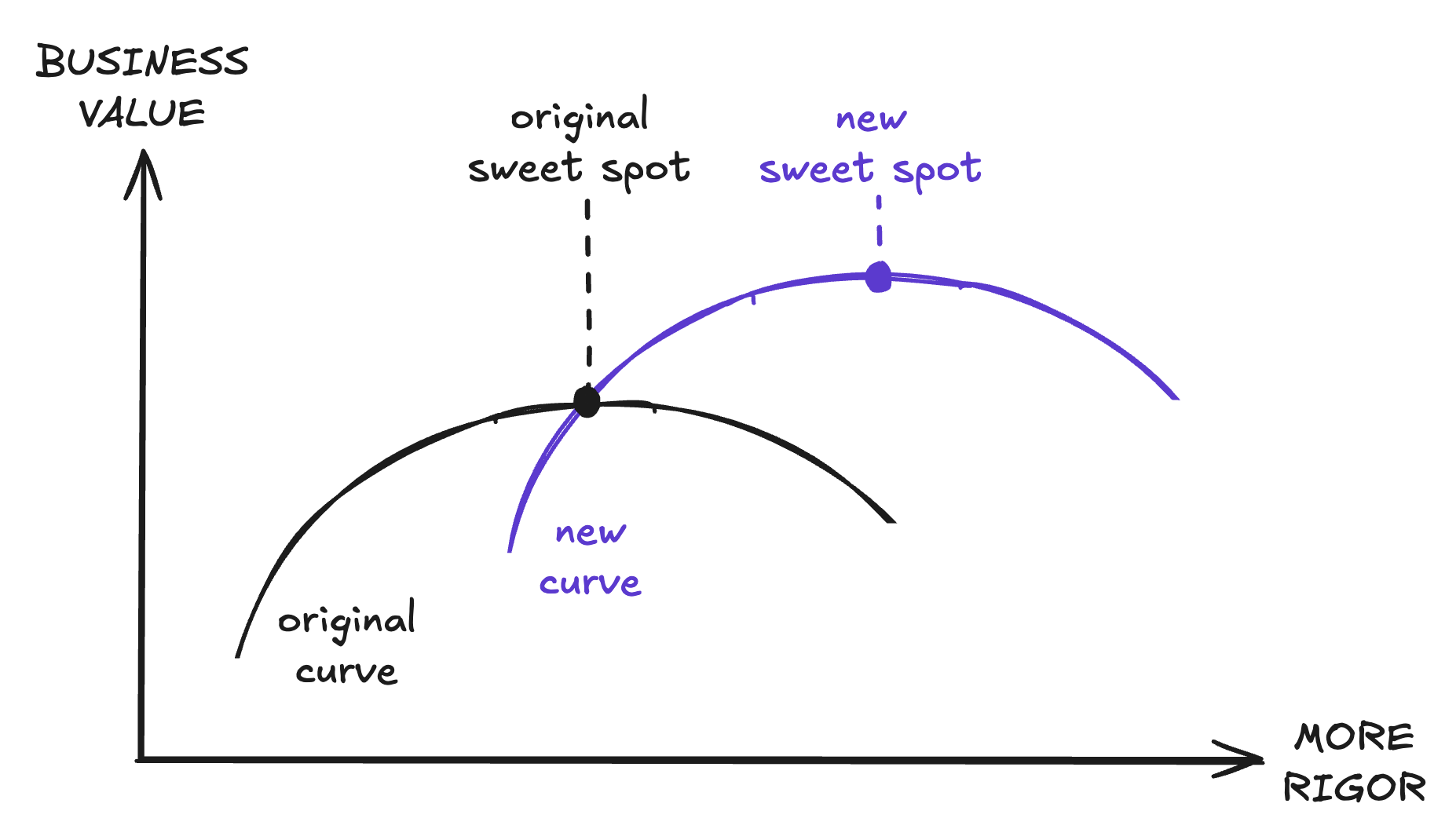
A major launch meaningfully inflects our user growth rate. We are now projecting 20x growth instead of 5x over the next year. Now, what looked like the sweet spot before is no longer sufficient to support the business in a year. What we would’ve previously deprioritized as overengineering is now an urgent company priority. We have to pull backend engineers from product teams to support a massive infrastructure upgrade.
This is constantly happening on every team at every company. As users and data and requirements grow over time, we need more processing, more storage, and run into more bottlenecks, bugs and edge cases. As the product is integrated into the critical workflows of large enterprise customers, reliability and performance become a higher priority. Systems that were previously sitting at the sweet spot become inadequate and now require an upgrade or rewrite to move up the curve.
This shows that the sweet spot on the speed-rigor spectrum isn’t a fixed point or an absolute truth. It needs to constantly evolve with business goals.
Startup vs big tech
Extrapolating further, we can also visualize why big companies prioritize rigor, while startups prioritize speed.
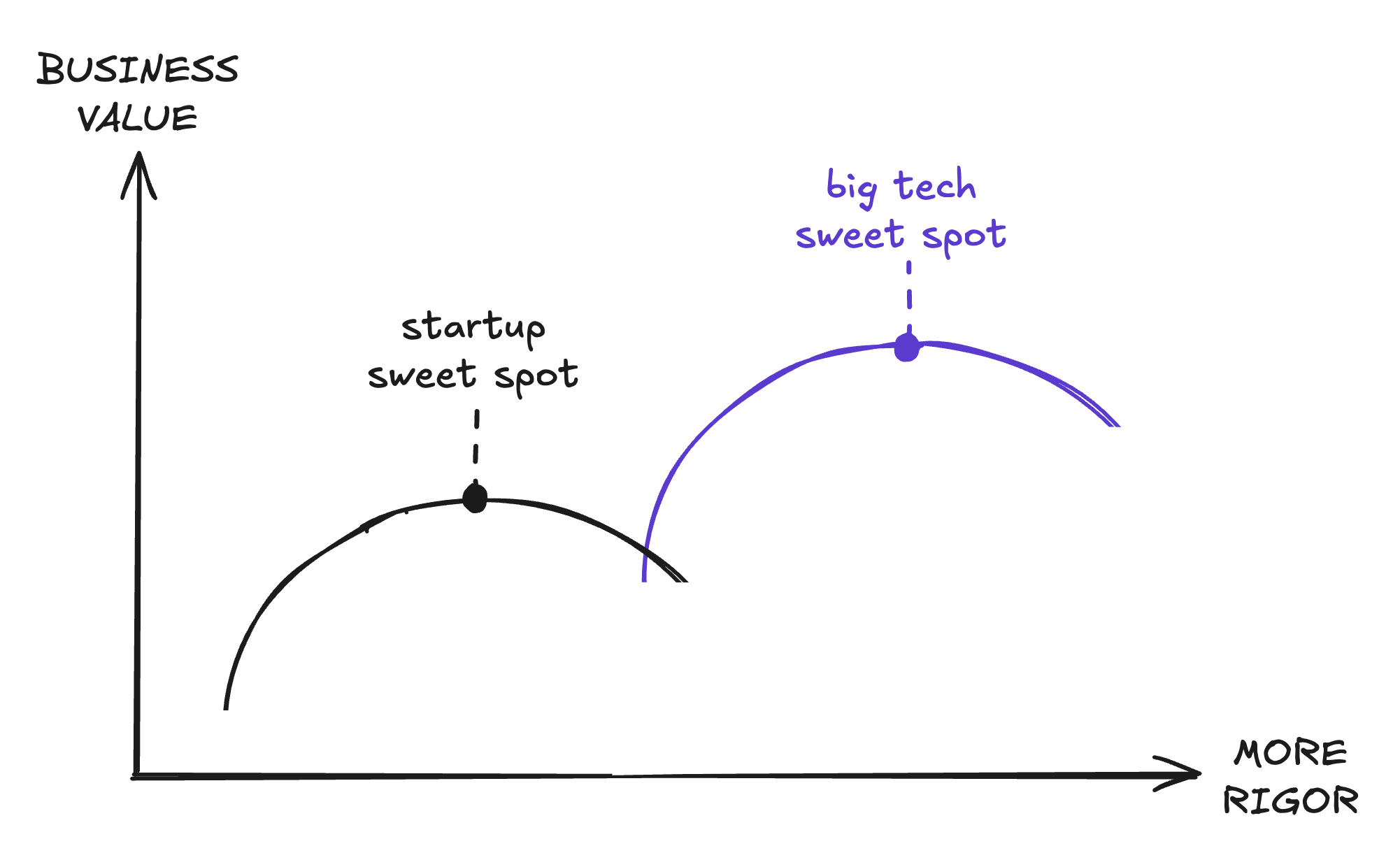
Big tech companies are defined by their incredible scale. That’s their competitive advantage. Think every web page ever created, every video, every social media post, every house and street, every email and chat message ever sent. This kind of scale creates unique challenges. Edge cases stop being edge cases. Problems that sound theoretical require serious investment on the order of hundreds of human years. On my first team at Google, our system processed 10-15 million events every second. Something my coworker said that stuck with me: if something has a once in a billion chance of happening, it’s going to happen in the next minute.
Most startups operate at a very different scale. We’re talking about millions of rows or requests, not billions. A large customer might be 5K seats, not 500K. The fundamental challenge is very different: scarcity. We never have enough money, people, or time. Our problem is not “How do we make this thing work reliably and quickly at scale?” but “How do we build the right thing fast enough to matter or pivot before we run out of funding?” We might be building and launching a new system with one other engineer over the next three weeks, not 8 engineers over the next year. If we can glue together some open source components or offload the problem cheaply to a vendor, it makes no sense to spend precious resources on a beautifully crafted custom solution that might end up getting scrapped in four months anyway.
Which environment is for me?
At one extreme, joining a team that works on a planet scale system at a big company means you get to learn from world-class experts on a technical subject. You learn what engineering and operational excellence mean at a level of rigor that is hard to experience anywhere else. In the future, even when you work on systems that operate at far smaller scale, you’ll have those lessons in your toolkit to apply when appropriate. In fact, this is a big reason why senior engineers from big tech are particularly sought after at late stage startups. They’ve seen what the “end game” looks like, and can bring those lessons to help evolve other systems towards that level of maturity.
However, when taken too far, rigor can become counterproductive. This famous video from 2010, affectionately referred to as “Broccoli Man and Panda Girl”, is a satire of what it feels like to try to launch a new feature at Google. When high rigor becomes an absolute virtue, it becomes really hard to ship. Best practices established to promote reliability and long term maintainability can become dead weight when we’re still trying to iterate and find product market fit. Processes created to mitigate risk can become bureaucratic nightmares that stifle progress and creativity.
At the other end of the spectrum, at an early startup, the rapid pace can be incredibly energizing. There are far fewer steps between coming up with an idea and seeing it solve problems for real customers. You can learn quickly from a tight iteration loop of shipping and getting user feedback. Your system may look simple next to a planet scale system from big tech, but it takes real creativity to find the 80% solution at 20% of the cost. And the time you saved can now be invested in iterating and solving the next problem.
But speed has its own challenges. The most obvious downside of “move fast” is “break things”. When speed is enshrined as an absolute virtue, there can come a point of reckoning where it’s actively holding back the business. For example, Facebook famously reset its motto in 2014 from “Move Fast and Break Things” to “Move Fast with Stable Infrastructure” because, paradoxically, moving too fast had created so much technical debt that it was slowing things down. Quote Zuckerberg at the time: “When you build something that you don't have to fix 10 times, you can move forward on top of what you've built.”
Additionally, a common pain point for engineers in a fast moving environment is thrash and burnout. You might feel you’re constantly moving from one half baked solution to the next, without the space and time to invest in long term foundations. You might be stressed from the non-stop stream of urgent fires and impossible timelines. After a while, you might feel your technical growth has plateaued, where you’re duct-taping the same components together over and over again for the next CRUD feature.
Conclusion
Ultimately, speed and rigor are not ideals we should subscribe to in a vacuum. The best engineers are not the ones who always try move fastest or always strive to build the most robust systems. They are the ones who can understand the context of the problem and the business in the current moment, and advocate for the right point on the spectrum. Sometimes that means duct-taping things together to learn and fail faster. Sometimes it means slowing down to move faster in the long term. That’s part of the craft of software engineering.
I once heard it put this way:
A good junior engineer is one who has mastered best practices.
A good senior engineer is one who knows when to ignore them.
Written by a human.